

Introduction
Apache Spark is a popular distributed computing framework and its extensively used in field of big data. Spark Ecosystem offers many attractive features like multiple language APIs (SQL,Python,R,Java and Scala), Spark Streaming, SparkML and GraphX library which makes it a Swiss army knife any big data tech arsenal.
Evolution
The following white papers formed a foundation for Spark Framework and many other distributed computing engines. These technologies have changed the world and inspired hundreds of systems through their ideas to tackle scale, reliability, and performance. (Highly Recommend To Read)
Google File System
:Google File System, a scalable distributed file system for large distributed data-intensive applications. This is the original inspiration for Hadoop.Google Map-Reduce
:MapReduce is a programming model and an associated implementation for processing and generating large data sets.
How Does It Work ?
Spark works on the principle of MapReduce. Users specify a map function that processes a key/value pair to generate a set of intermediate key/value pairs, and a reduce function that merges all intermediate values associated with the same intermediate key. Many real world tasks are expressible in this model.
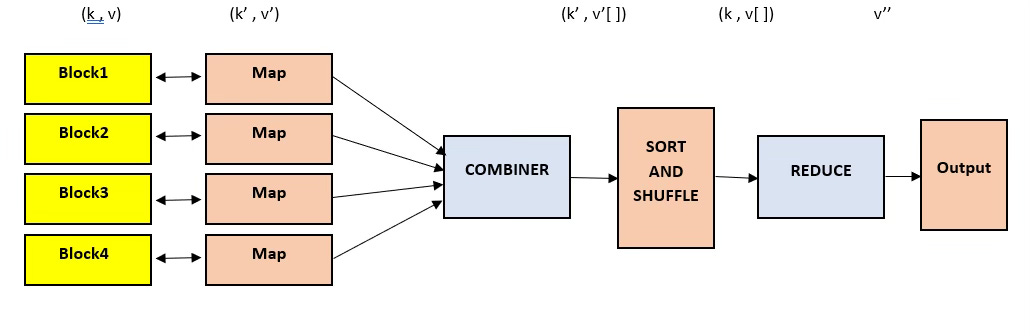
Different Phases of MapReduce:-
MapReduce model has three major and one optional phase.
Mapping :
Shuffling and Sorting
Reducing
Combining (Optional)
Mapping
each worker node applies the map function to the local data, and writes the output to a temporary storage. A master node ensures that only one copy of the redundant input data is processed.
Shuffling and Sorting
worker nodes redistribute data based on the output keys (produced by the map function), such that all data belonging to one key is located on the same worker node.
Combining (optional)
The combiner phase is used to optimize the performance of MapReduce phases. This phase makes the Shuffling and Sorting phase work even quicker by enabling additional performance features in MapReduce phases. Aggregating or merging intermediate key-value pairs generated during the mapping phase before they are sent to the reducing phase
Reducing
worker nodes now process each group of output data, per key, in parallel.
EXAMPLE
This is a very simple example of MapReduce. No matter the amount of data you need to analyze, the key principles remain the same.
Assume you have five files, and each file contains two columns (a key and a value in Hadoop terms) that represent a city and the corresponding temperature recorded in that city for the various measurement days. The city is the key, and the temperature is the value. For example: (Toronto, 20). Out of all the data we have collected, you want to find the maximum temperature for each city across the data files (note that each file might have the same city represented multiple times).
Using the MapReduce framework, you can break this down into five map tasks, where each mapper works on one of the five files. The mapper task goes through the data and returns the maximum temperature for each city.
For example, the results produced from one mapper task for the data above would look like this: (Toronto, 20) (Whitby, 25) (New York, 22) (Rome, 33)
Assume the other four mapper tasks (working on the other four files not shown here) produced the following intermediate results:
(Toronto, 18) (Whitby, 27) (New York, 32) (Rome, 37) (Toronto, 32) (Whitby, 20) (New York, 33) (Rome, 38) (Toronto, 22) (Whitby, 19) (New York, 20) (Rome, 31) (Toronto, 31) (Whitby, 22) (New York, 19) (Rome, 30)
All five of these output streams would be fed into the reduce tasks, which combine the input results and output a single value for each city, producing a final result set as follows: (Toronto, 32) (Whitby, 27) (New York, 33) (Rome, 38).
Architecture
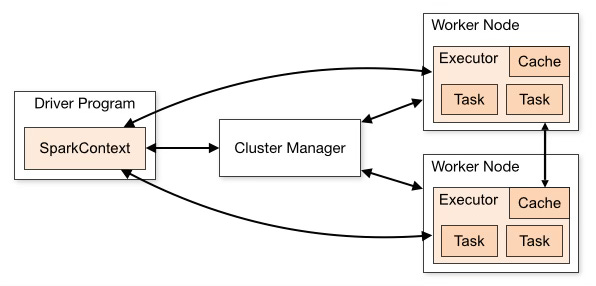
Apache Spark has a hierarchical primary/secondary (or master/slave) architecture. The Spark Driver is the primary node that controls the cluster manager, which manages the secondary (worker) nodes and delivers data results to the application client.
Spark applications run as independent sets of processes on a cluster, coordinated by the SparkContext object in your main program.
To run on a cluster, the SparkContext connects to cluster manager, which allocate resources across applications. Once connected, Spark acquires executors on nodes in the cluster, which are processes that run computations and store data for your application. Next, it sends your application code (defined by JAR or Python files passed to SparkContext) to the executors. Finally, SparkContext sends tasks to the executors to run.
Resilient Distributed Datasets (RDDs)
Resilient Distributed Datasets (RDDs) are fault-tolerant collections of elements that can be distributed among multiple nodes in a cluster and worked on in parallel. RDDs are a fundamental structure in Apache Spark.
Spark loads data by referencing a data source or by parallelizing an existing collection with the SparkContext parallelize method of caching data into an RDD for processing. Once data is loaded into an RDD, Spark performs transformations and actions on RDDs in memory—the key to Spark’s speed. Spark also stores the data in memory unless the system runs out of memory or the user decides to write the data to disk for persistence.
Each dataset in an RDD is divided into logical partitions, which may be computed on different nodes of the cluster.
Users can perform two types of RDD operations:
Transformations : Transformations are operations applied to create a new RDD.
Actions : Actions are used to instruct Apache Spark to apply computation and pass the result back to the driver.
Spark supports a variety of actions and transformations on RDDs. This distribution is done by Spark, so users don’t have to worry about computing the right distribution.
Lazy Execution
Spark handles the execution of data transformations and actions in a deferred manner, rather than immediately executing them when they are defined. This approach is helpful in generating optimal query execution plans resulting in high speeds and reduced I/Os (disk read/write).
Spark creates a Directed Acyclic Graph (DAG) to schedule tasks and the orchestrate worker nodes across the cluster. As Spark acts and transforms data in the task execution processes, the DAG scheduler facilitates efficiency by orchestrating the worker nodes across the cluster. This task-tracking makes fault tolerance possible, as it reapplies the recorded operations to the data from a previous state.
Datasets And Dataframes
In addition to RDDs, Spark handles two other data types: DataFrames and Datasets. These are higher level apis built on top of RDDs.
DataFrames are the most common structured application programming interfaces (APIs) and represent a table of data with rows and columns. Although RDD has been a critical feature to Spark, it is now in maintenance mode.
Datasets are an extension of DataFrames that provide a type-safe, object-oriented programming interface. Datasets are, by default, a collection of strongly typed JVM objects, unlike DataFrames.
Spark SQL enables data to be queried from DataFrames and SQL data stores, such as Apache Hive. Spark SQL queries return a DataFrame or Dataset when they are run within another language.
Available Solutions
SAS (Software As Service) : databricks , Vanilla Spark (Available in all major cloud provides)
Useful Resources :